Nay Zaw Aung Win

Mechanical Engineer by degree,
Data Scientist by passion!
View My LinkedIn Profile
Reddit NLP Analysis of Posts/Submissions made by Users w/ Smoking Addiction
Project description: The goal of this project is to analyze changes in linguistic patterns of the Reddit users before and during the COVID-19 pandemic.
This project was presented at the ICWSM 2022 conference, which was held in Atlanta, Georgia, USA. The code for this project can be found in my Github repo.
1. Project Motivation: Are people with smoking addiction getting the help and attention that they need during the COVID-19 pandemic?
The outbreak of the COVID-19 pandemic created global social distancing restrictions, which forced millions of people to stay at home. The imposed seclusion could cause further marginalization of the individuals with Substance Use Disorders (SUDs). With so much attention and prioritization of health-care services for the COVID-19 patients, it is likely that the individuals with SUDs, such as those with smoking addiction, who are feeling the secondary effects of the pandemic were forgotten.
2. Project Workflow Chart
3. Data and Preprocessing
First, the Python Reddit API Wrapper (PRAW) was used to scrape all submissions and comments from the subreddit “r/stopsmoking” that were published on or after January 1, 2018 until March 1, 2022. We consider the category of each post as either a comment post or a submission post. Submissions are the main posts made by a user that can start a discussion thread, whereas comments are responses to a given submission or a submission’s reply. A total of 35,425 submissions and 372,144 comments were retrieved. First, both submissions and comments were split into two subsets of data based on March 11th, 2020 – the date when COVID-19 was declared as a pandemic (therefore there were a total of 4 datasets). Next, the actual text bodies of each of the four datasets were cleaned by removing the punctuation, unicode characters, URLs and other non-alphanumeric characters. Different python NLP packages were used in this project: NLTK for n-grams, TextBlob for sentiment polarity computations, BERTopic for topic extraction, and gensim for Word2Vec embeddings.
4. Results
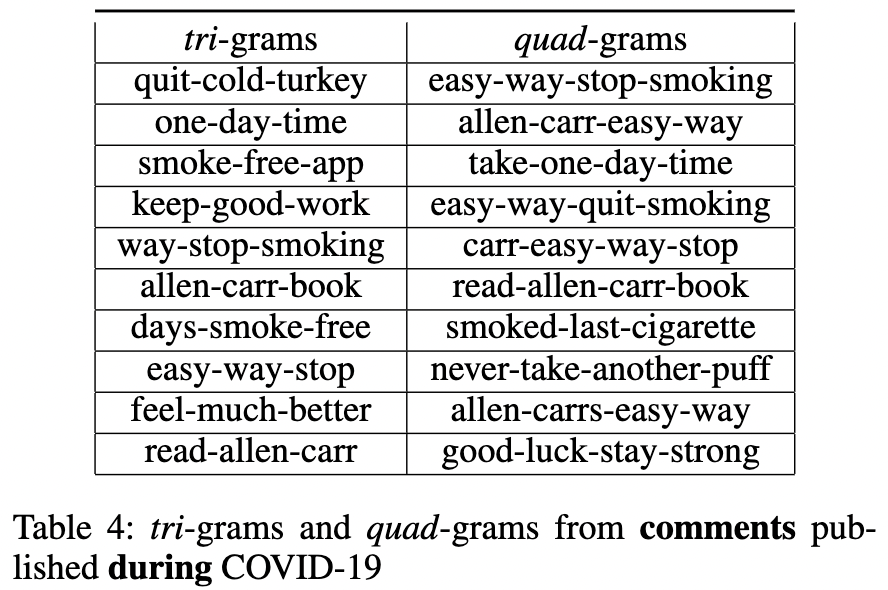
n-grams
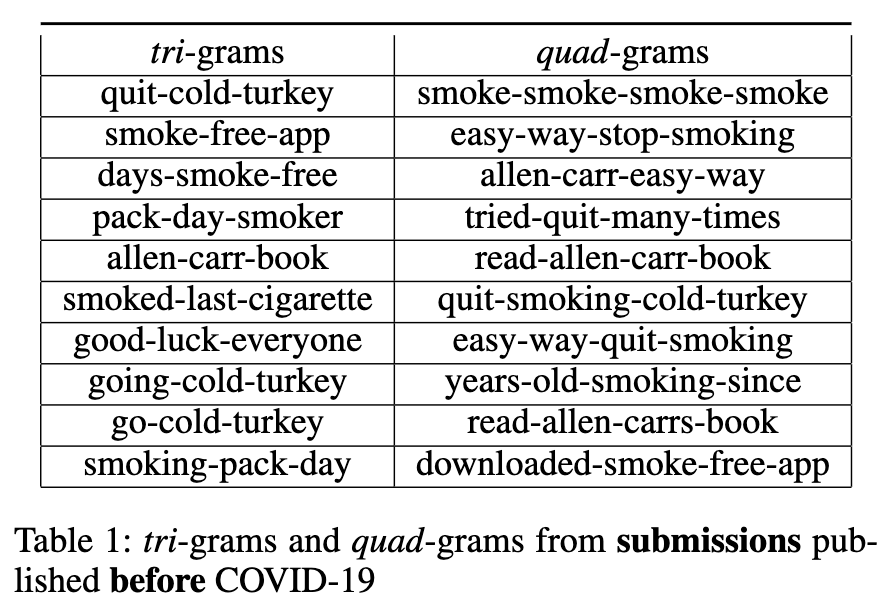
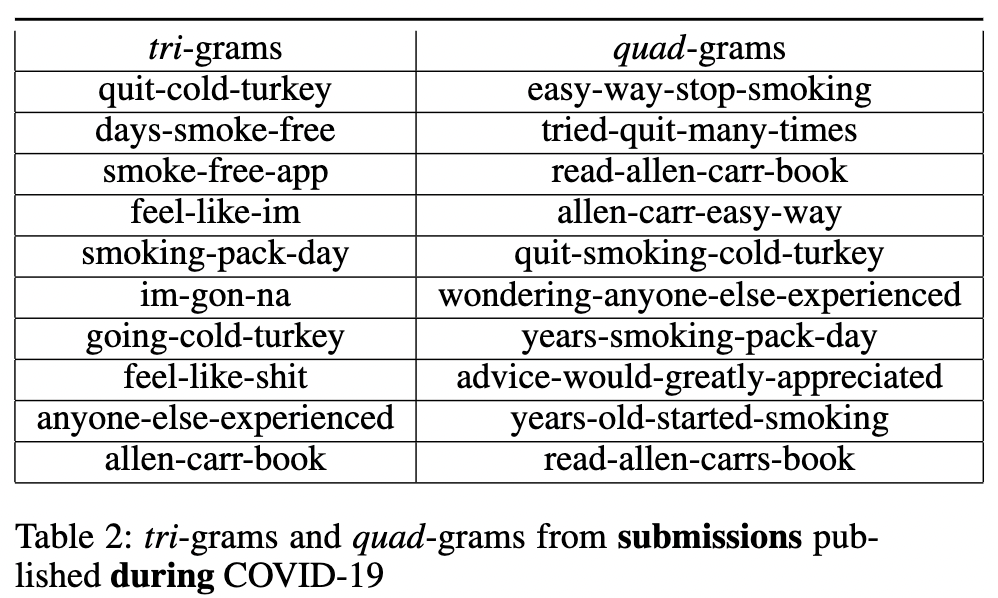
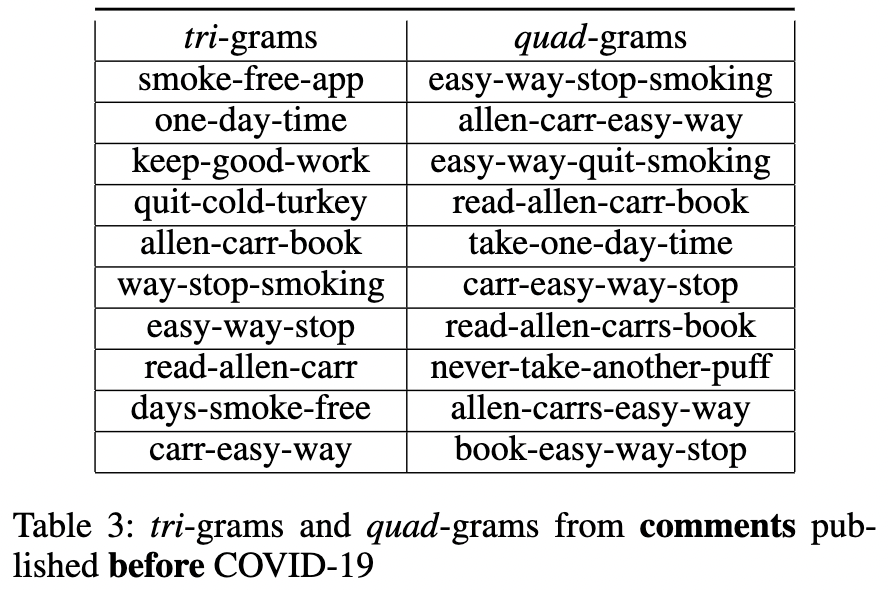
An n-gram is the most frequently occurring sequence of N words in a corpus. The top-10 tri-grams (n=3) and quad-grams (n=4) extracted from each of the four datasets are listed in the Table 3, Table 4, Table 1, and Table 2. First, we observe that in both comments and submissions, that were published both before and after COVID-19 was officially declared to be a pandemic, the book written by Alan Carr called “Alan Carr’s Easy Way to Stop Smoking” (Carr 2004) is the most frequently referenced resource. Although all four tables share similarities in their n-grams, there is a subtle difference between Table 1 and Table 2 in terms of the polarity of the words in their n-grams. Table 2 contains n-grams that share their experiences while at the same time seeking advice from the community. On the other hand, when we consider polarity values, Table 1 contains n-grams that carry a more neutral tone and are also found in Table 2. This may suggest that staying at home during the pandemic might have caused them to seek extra emotional support and advice from their peers to achieve the goal of smoking cessation. No significant differences can be spotted between Tables 3 and Table 4 as the n-grams in both tables appear to be mostly positive.
Sentiment Polarity Analysis
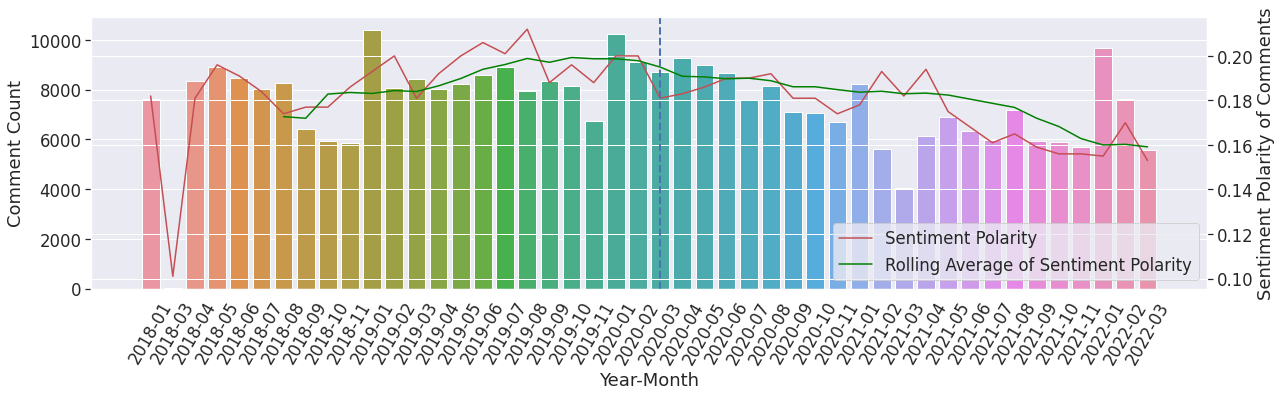 Figure 1: Plot, representing the monthly average sentiment polarity score of comments, overlaid on the histogram that shows the number of comments published each month since January 2018.
Figure 1: Plot, representing the monthly average sentiment polarity score of comments, overlaid on the histogram that shows the number of comments published each month since January 2018.
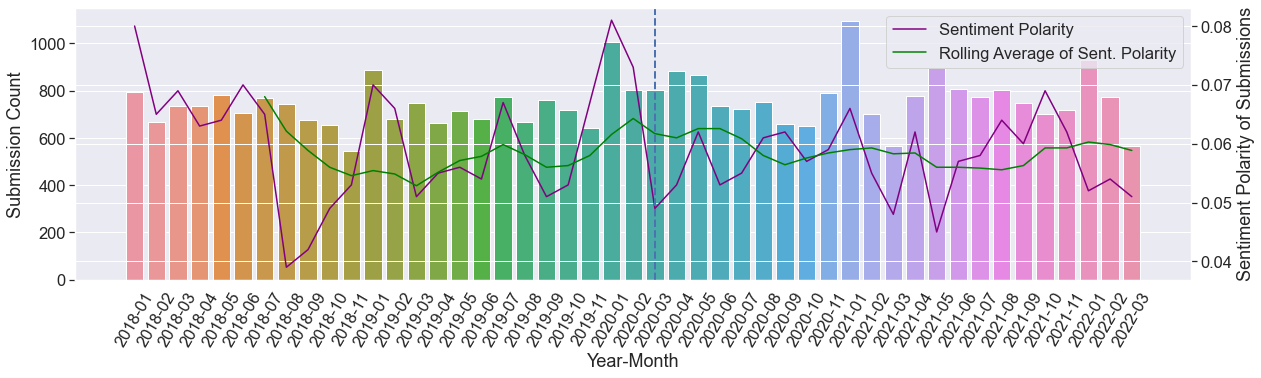 Figure 2: Plot, representing the monthly average sentiment polarity score of submissions, overlaid on the histogram that shows the number of submissions published each month since January 2018.
Figure 2: Plot, representing the monthly average sentiment polarity score of submissions, overlaid on the histogram that shows the number of submissions published each month since January 2018.
To further investigate how sentiment polarities changes, the average sentiment polarity value was plotted for each month for comments (shown in Figure 1) and for submissions (shown in Figure 2) separately. Both these plots show three main aspects – 1) average value of sentiment polarity per each month, 2) its moving average over time and, 3) distribution of total number of posts made in each month, as a histogram. Two main observations can be made on Figure 1. First, we see on the right edge of the plot that the average polarity for each month comes out to be positive. This suggests the responses to the submissions have been, by and large, encouraging and empathetic. Secondly, we observe that the sentiment polarity score for the comments has decreased gradually since the start of the pandemic where the start date of the pandemic is marked with a vertical dashed line on the plot. Figure 2 shows that relative to comments, submission posts have lower positive polarity. This plot also shows that sentiment polarity score from month to month for submissions is more chaotic compared to the comments with no specific trend (p >0.05).
Topic Shifts
Figure 3 shows the top-6 topics extracted from the four different subsets of data – before and during the pandemic for both comments and submissions separately. These topics highlight interesting aspects as follows. Comments: 1) before the pandemic, top-6 topics include vaping, how to fight cravings, reading Allan Carr’s books on ways to quit smoking, being drunk at a bar, different kinds of discomforts due to withdrawals, and triggers and cravings; 2) during the pandemic, top-6 topics include vaping, distracting themselves from cravings and resist, being drunk and hangovers, rambles about fighting addictions in general, smoking weed/cannabis, and fighting cravings; 3) When we compare the topics before and during the pandemic, discussions about drinking alcohol and hangovers jumped to be a more important topic during the pandemic than earlier; 4) Also, there is little to no discussion about reading books specific to ways on how to quit smoking; 5) We also noticed that discussion about marijuana/cannabis is one of the most important topics during the pandemic compared to earlier time period. These insights may suggest that at a high-level individuals might be fighting their urges to quit smoking but may be due to the pandemic, there are increased discussion about them consuming alcohol and hangovers as well as marijuana. Further analysis is required to investigate if individuals are using these alternatives as coping mechanisms during the pandemic while fighting the withdrawal symptoms and triggers on their journey to quit smoking. For Submissions: 1) the top topics of discussions before the pandemic are about vaping and cigarettes addictions, pulmonary issues including cough, asthma, and bronchitis, different withdrawal symptoms including depression, and anxiety, strong cravings to smoke, consuming alcohol (at a bar), failed to quit and relapsed; 2) during the pandemic, the most important topic of discussion is about coughing, breathing and different pulmonary issues, seeking advice on how to quit and sharing their personal stories about when they started smoking, discussions about cravings, reading books about how to quit smoking, discussions about cravings, and drinking with friends and hangovers; 3) It is worth noticing that these topics during the pandemic are more personal through sharing their personal stories in order to seek advice on how to quit smoking and also sharing about consuming alcohol with their friends which we do not see clearly before the pandemic; 4) since some of the common symptoms of COVID-19 is shortness of breathe and cough, this might be the reason why we see discussions about pul- monary issues is the main topic of discussion; 5) stay-at-home orders to mitigate the spread of COVID-19 virus also might be the factor for individuals to open up online and share more of their personal stories than earlier.
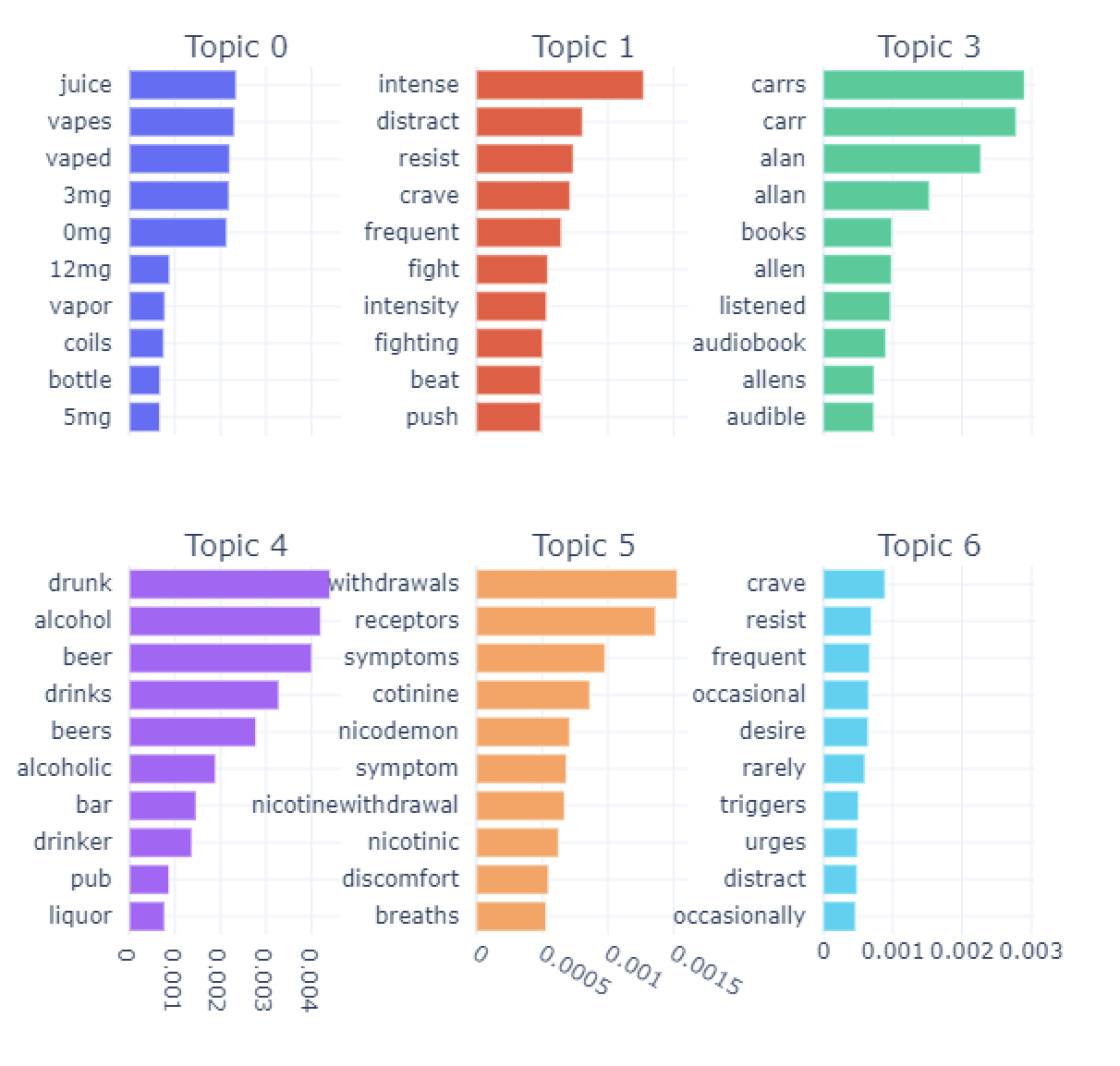 Figure 3a: Topics for comments, before COVID-19.
Figure 3a: Topics for comments, before COVID-19.
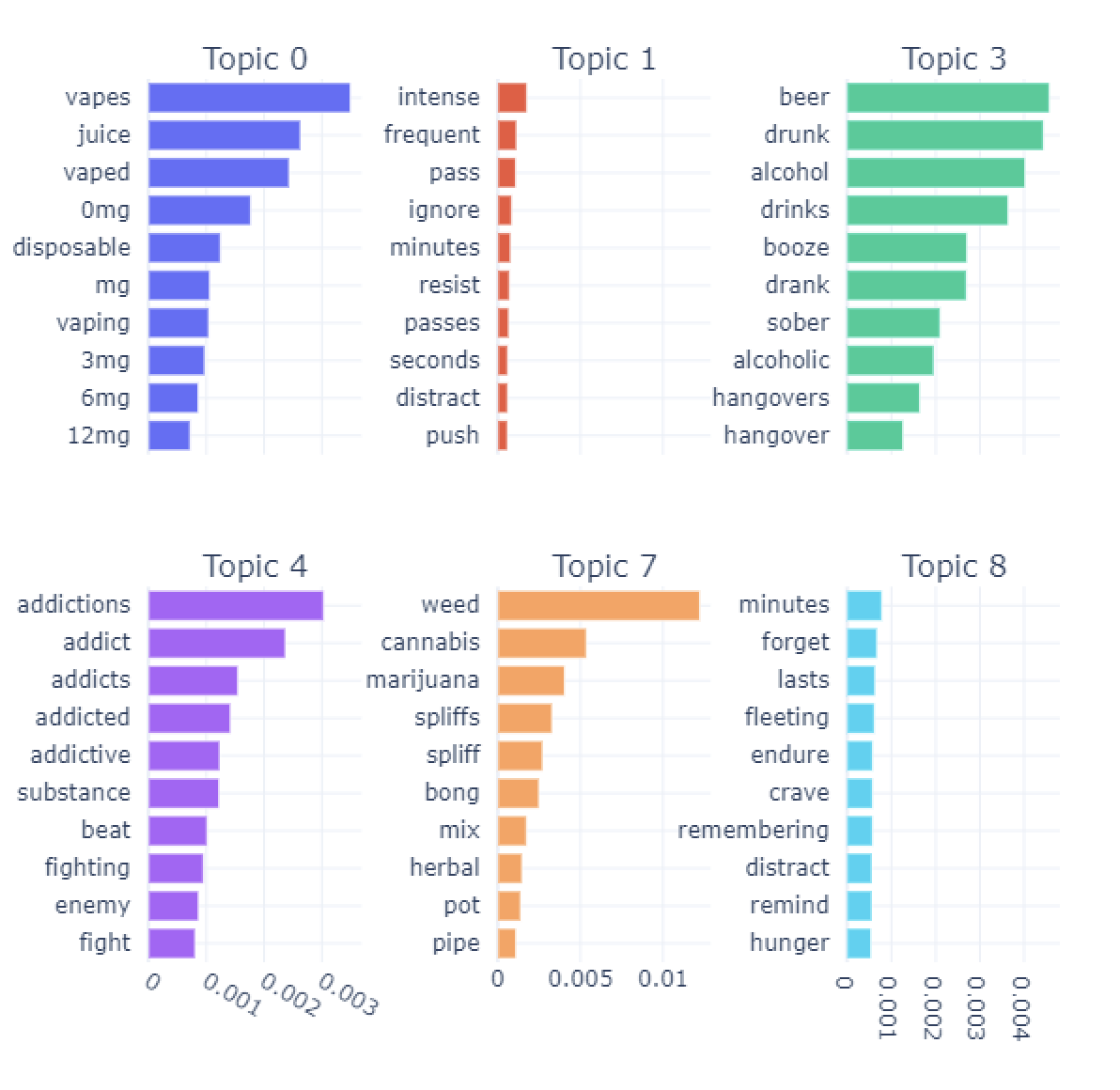 Figure 3b: Topics for comments, duriing COVID-19.
Figure 3b: Topics for comments, duriing COVID-19.
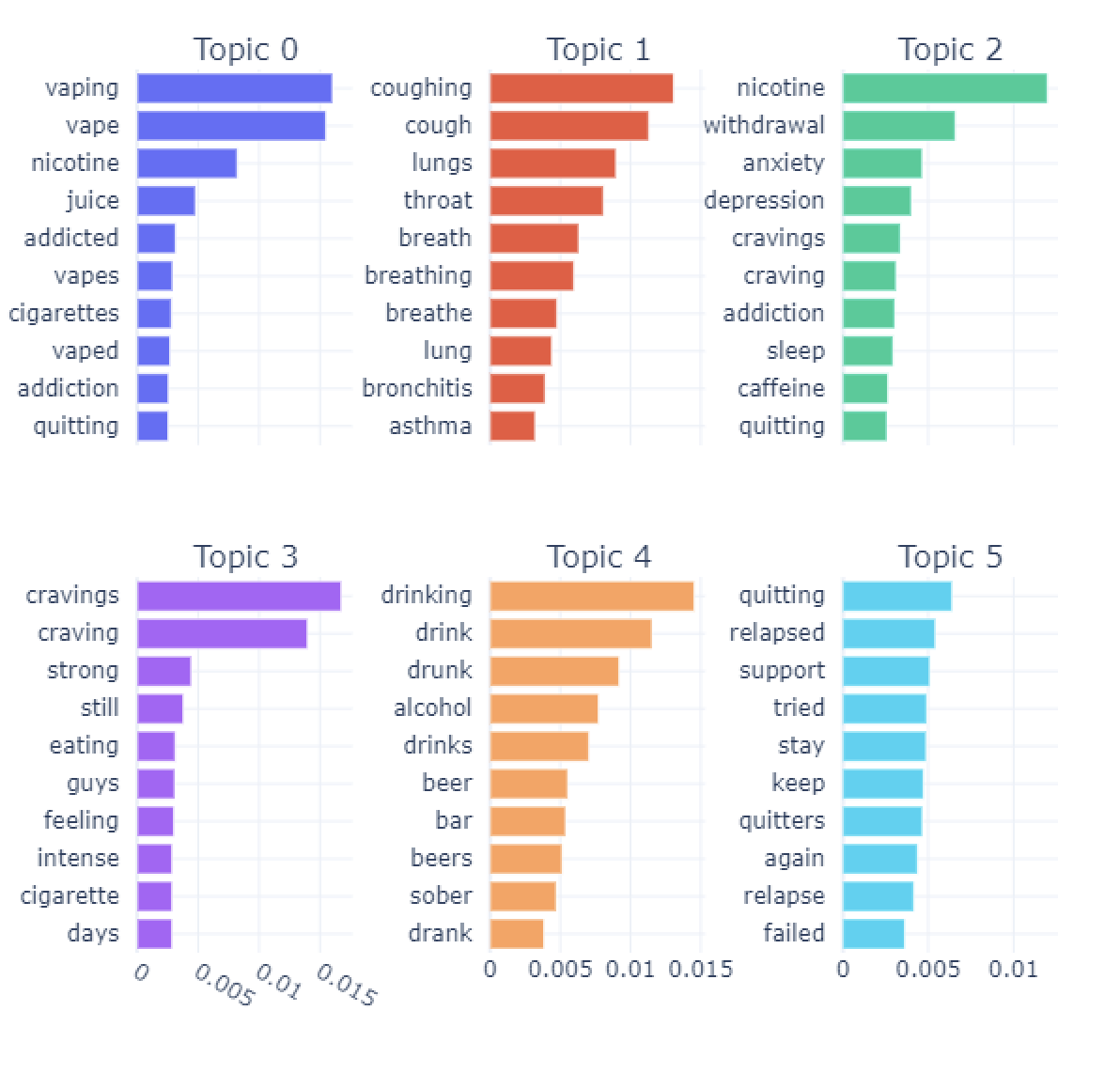 Figure 3c: Topics for submissions, before COVID-19.
Figure 3c: Topics for submissions, before COVID-19.
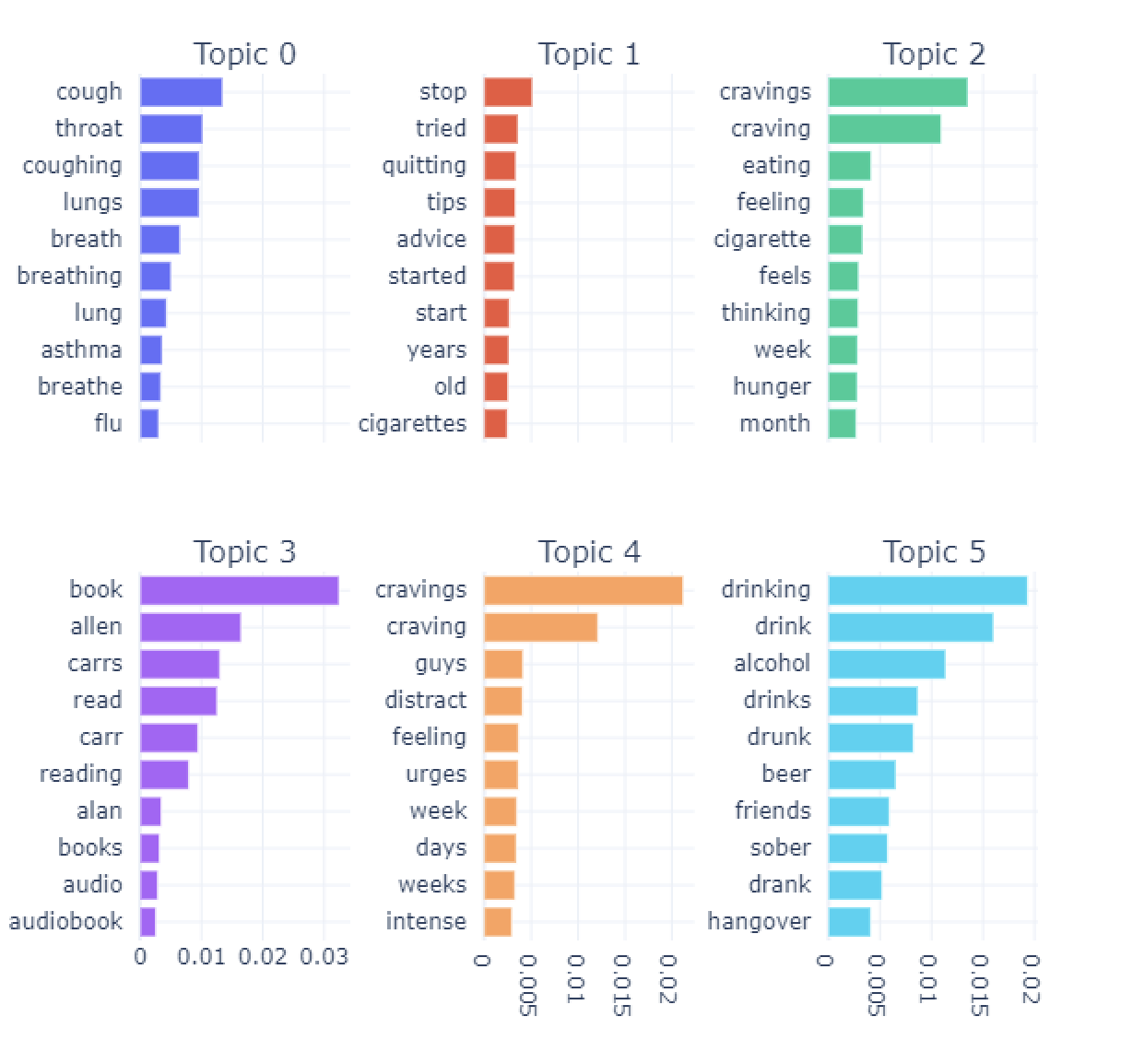 Figure 3d: Topics for submissions, during COVID-19.
Figure 3d: Topics for submissions, during COVID-19.
Semantic Shifts using Neural Embeddings
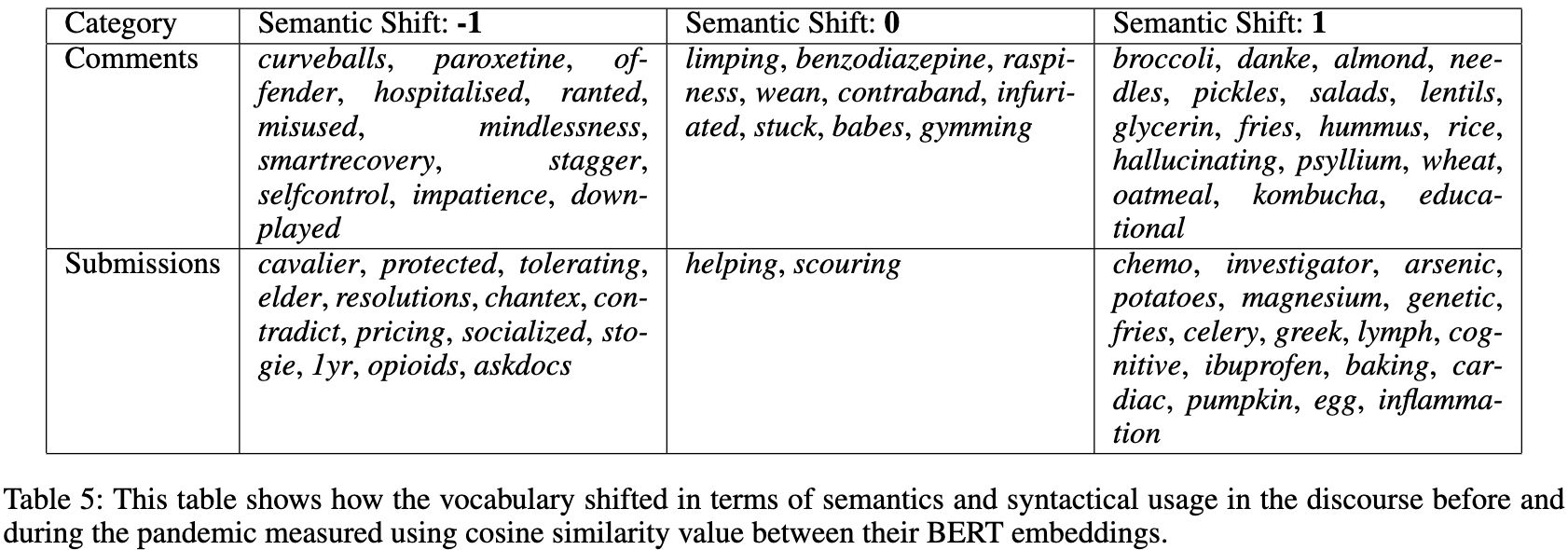
We first represent the vocabulary in comments and submissions (two categories of posts) by further separating them out based on whether a post was made before or during the pandemic. For each category of posts, we first identify the common vocabulary in the datasets before and during the pandemic. To ensure the neural embeddings will be of same size for vocabulary, we clean the posts made before and during the pandemic. We leverage the Word2Vec Approach to convert the vocabulary into vector format. We then use keywords in the common vocabulary to measure the cosine similarity between its vector representation before the pandemic and during the pandemic. This similarity value is used as the main measure to methodically represent the amount of shift due to the pandemic for a given keyword. Please note that the shift value has a range from 1 meaning exactly opposite, to 1 meaning exactly the same, with 0 indicating orthogonality. Table 5 shows a sample set of these keywords with varying values of semantic shift measured through computing cosine similarity
4. Discussion
This analysis extracts different linguistic cues from discussions that emphasize on their shift during the pandemic. Specifically, we noticed from the topics that during the pandemic there is an increased mentioning of several personal stories as well as honest struggles (for example, consuming alcohol, marijuana) to fight the triggers. Semantic shift using similarity between the neural embeddings also suggest that smoking-related keywords are shown to be having values lesser than 0 suggesting an opposite behavior between before and during the pandemic. These insights corroborate with the existing medical and clinical studies that the pan-demic has made it difficult for individuals with addictions. Note that given the focus on only one specific subreddit as well as one kind of addiction disorder, the impact of the results might be limited. As part of future work, the project will be expanded to include several other addiction disorders as well as consider different forums, to evaluate the impact of COVID-19 on individuals in these contexts.
For more details see GitHub Flavored Markdown.